Meridian Design Doc 1: Model Exploration
👉
Introduction
MERidian stands for Measure, Evaluate, Reward, the three steps of the impact evaluator framework. The Meridian project aims to create an impact evaluator for “off-chain” networks. I.e. a network of nodes that do not maintain a shared ledger or blockchain of transactions.
This doc proposes a framework and model for Meridian that will cater initially for both the Saturn payouts system and the SPARK Station module. For a bonus point, it should be able to cater for any Station module. We believe that trying to generalise beyond these few use cases at this point may be counterproductive.
We will structure this design doc based on the three steps of an Impact Evaluator (IE), measure, evaluate and reward, and we look at our use cases against key criteria.
Measure
In the measurement step, we refer to each atomic item that gets measured as a job. For example, each retrieval served by a Saturn node is a job. For Spark, each retrieval made from an SP is a job. In order to proceed to the Evaluation step, we need to gather together a set of the jobs, or some summary statistics about the jobs, in one location for each evaluation epoch. We begin with the naive solution.
Models
Naive Model
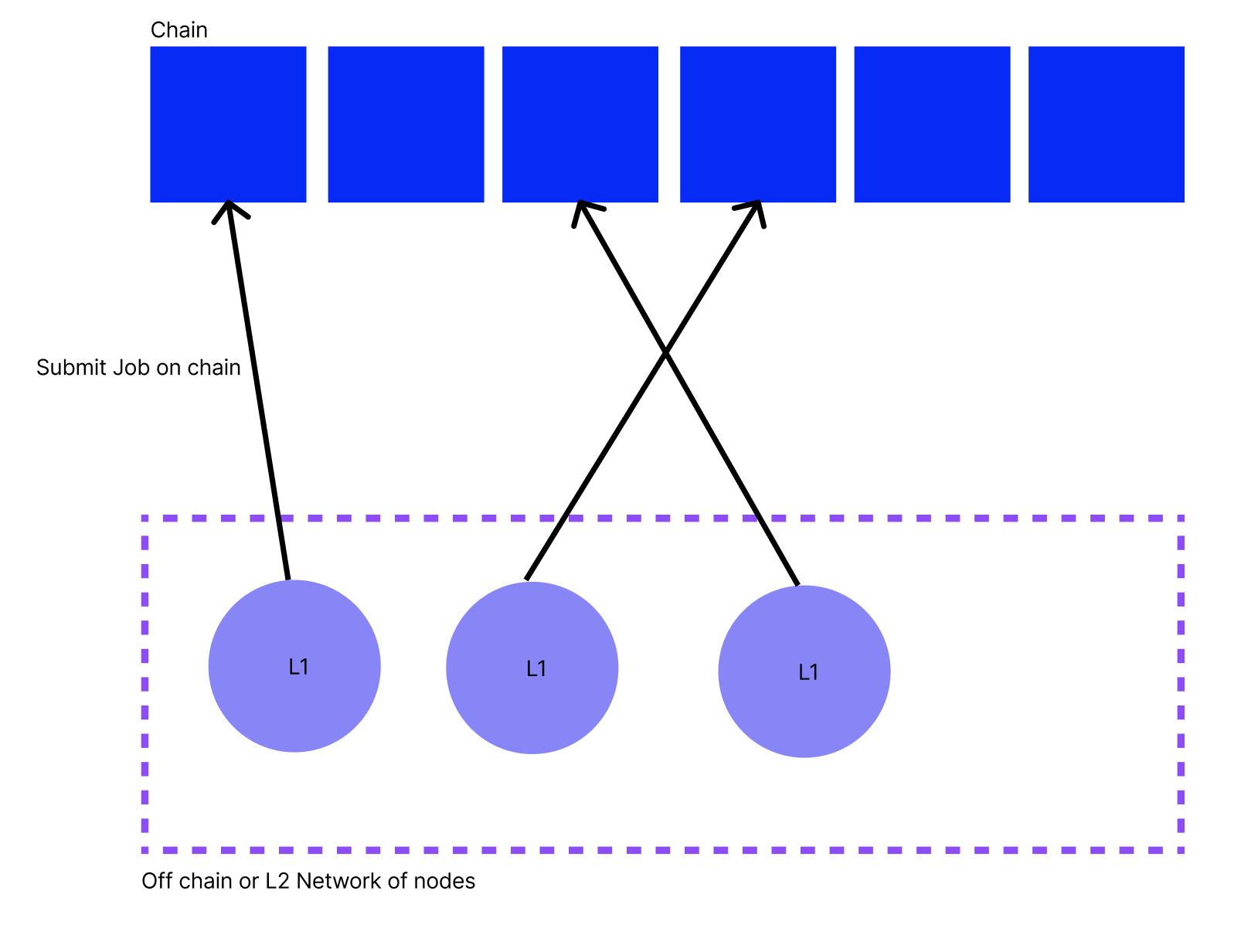
The naive solution is for each Impact Evaluator system (Saturn, Spark) to have a measurement smart contract on chain and for each node in the network to submit each job they perform into this smart contract on chain. This would allow the evaluation smart contract to access all the jobs in each epoch. However, this the naive solution is unsuitable for the majority of use cases for the following reasons:
- Scalability: The chain may not be able to deal with a large number of jobs submitted. E.g. Saturn creates 137M jobs each day and, for logs in an epoch, we have transactions on chain per epoch.
- Privacy: The details included in each job may be private.
- Fraud: The nodes in the network may be able to submit fraudulent logs to increase their impact, and therefore their rewards, in the network.
We analyse Saturn and Spark in the naive solution, based on these criteria:
| Scalability | Privacy | Fraud | |
|---|---|---|---|
| Saturn | We cannot submit all the logs on chain. There are far too many. | Clients of Saturn are highly unlikely to be happy with retrieval job info being publicly available | Saturn nodes can easily self deal if they are allowed to submit jobs onto the chain. |
| Spark | The Spark orchestrator (smart contract) can rate limit the number of jobs. However, it would be better if not all jobs were submitted on chain so that Spark can scale. | This data could be made public. In fact, if Spark joins the SP Reputation WG, then the jobs could end up in a public database | 1. Since job records can be cross-referenced with orchestrator records, they cannot “self-deal”. 2. Since they may be asked to retrieve from, and create a signature chain with, any SP, they cannot fake the signatures without being detected. |
We now look at some more advanced solution that aim to move the needle on one or more of the three criteria.
IPC Subnets
To target scalability, one option is to look into Filecoin’s scalability solution: IPC subnets - would they be able to handle the number of jobs that these networks would like to handle? However, IPC subnets would not move the needle on either privacy or fraud beyond the naive solution.
Off Chain Storage of Jobs
Another simple fix for scalability is to submit all the jobs into an off chain data store like Pando, Ceramic or Tableland. The evaluation contract would then simply need to know where to find all the jobs that occurred in a given epoch in order to begin the evaluation step. Again, this does not move the needle on privacy or fraud beyond the naive case.
Summary Statistics and Commitment on chain
Another improvement to the naive solution is for each node in the network to record their jobs and then submit on chain a summary of their jobs over each epoch, along with a commitment that the jobs were performed correctly. This approach moves the needle on two of the three criteria: scalability, privacy.
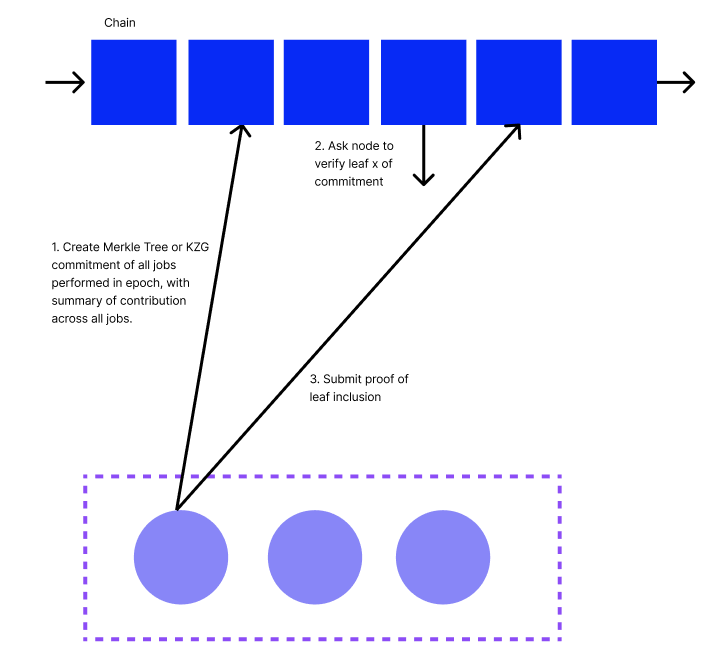
This improves scalability as we now only have transactions per epoch where is the number of nodes in the network. It is likely that unless each node is only submitting one job per IE epoch.
This also improves privacy as each node does not submit the raw details of each job on chain. Instead they keep this information local and only submit a summary of their contribution, a commitment of all jobs, along with a proof of job inclusion into the commitment if required. This proof could be made in zero knowledge.
However, this does not prevent fraud if a fraud vector is available in the naive case. For example, self dealing in the Saturn network is not mitigated here.
In the Spark network, each Station will submit a Merkle root or KZG commitment of its retrievals on chain each epoch, along with the summary of how many successful retrieval it has made.
N.B. Here the measurement step ends when a node has self recorded its jobs. The above protocol includes half of the Evaluation step as a node is calculating its own summary based on the evaluation function.
Centralised Orchestrator & Fraud Detection
In the Saturn network, each L1 node sends jobs to the centralised Saturn orchestrator. These measurements are collected by a centralised entity because of the privacy and fraud constraints on the Saturn network. More generally, if any network cannot find a way to mitigate the fraud vectors, i.e. it cannot create a robust proof of valid job, then they should go for this approach.
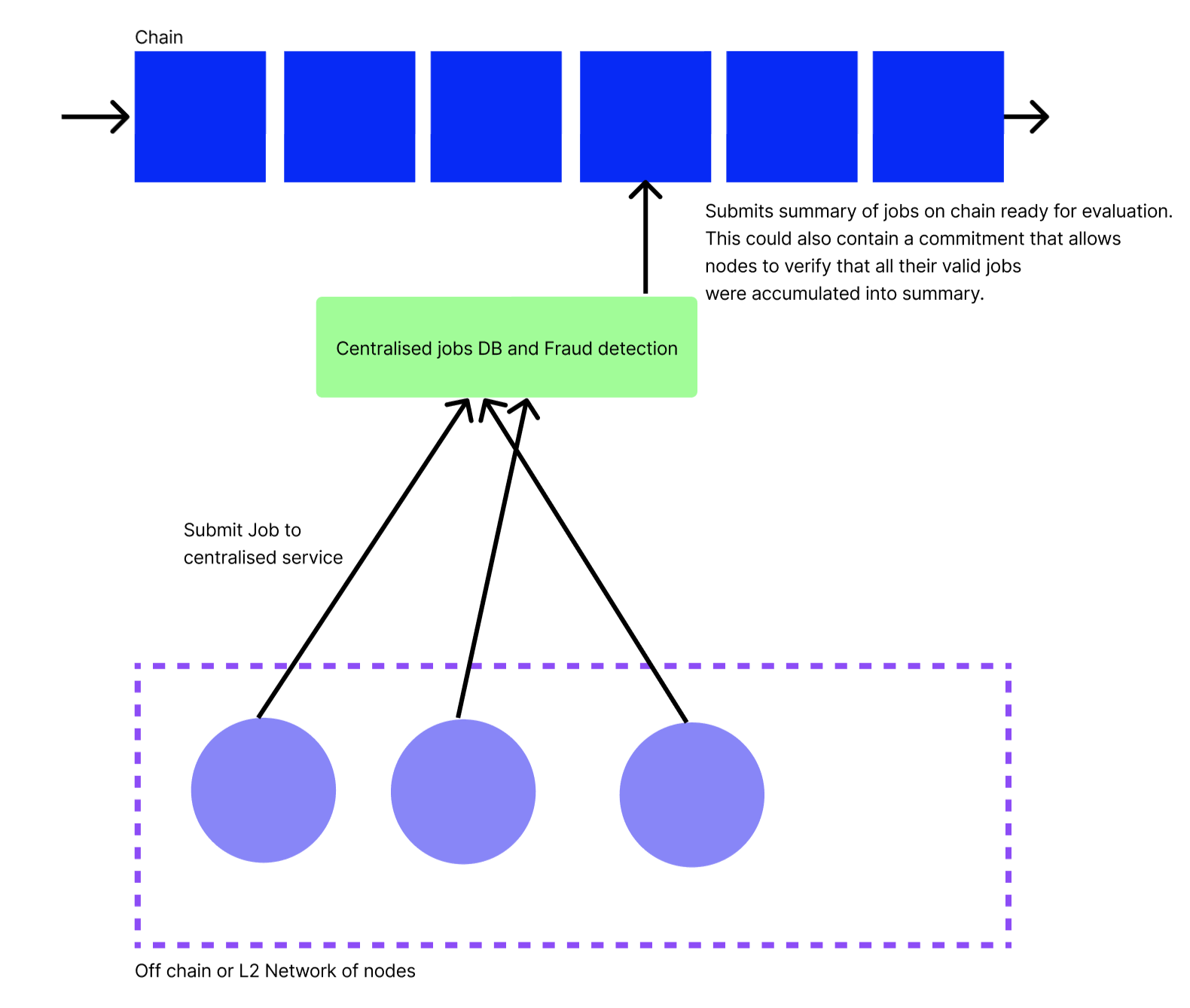
This solution improves scalability, privacy and fraud in the obvious ways. However, it is at the massive cost of centralisation as compared to the naive case.
Despite the centralisation, there are ways that we can provide verifiability to the nodes in the network that their non-fraudulent jobs were included in the summary.
Solutions compared to Naive Model
| Scalability | Privacy | Fraud | Trustlessness | |
|---|---|---|---|---|
| IPC Subnets | Much more scalable | No difference from naive solution | No difference from naive solution | No difference from naive solution |
| Off chain job storage | Much more scalable | No difference from naive solution | No difference from naive solution | No difference from naive solution |
| Commitment & epoch summary on chain | For n nodes, O(n) records on chain per epoch | Jobs are stored locally by each node and nowhere else. Proof of job inclusion in commitment can be masked by ZKPs | No difference from naive solution | No difference from naive solution |
| Centralised job database & fraud detection | Much more scalable | Much more private | Fraud detection can be run on jobs | Worse than naive solution. However, we can ensure that nodes can verify their valid logs counted towards their evaluation using cryptographic techniques. |
Data Model
General measurement data model
The data model for the measurement step is structured such that the generic job fields are in the outer scope. Then the fields that are used as part of the evaluation function (more below) re included in the evaluation fields block. Then all additional fields are in the additional fields block
{
"job_id": "<UUID or CID>", // unique job id
"peer_id": "<Libp2p Peer ID>", // Who completed the job
"started_at": "Timestamp", // when did the job begin
"ended_at": "Timestamp", // when did the job end
"evaluation_fields": [{ // fields that contribute to the impact evaluation
"name": "<name of evaluation field>",
"type": "<data type of evaluation field>",
"value": "<value of evaluation field"",
},{
"name": "<name of evaluation field>",
"type": "<data type of evaluation field>",
"value": "<value of evaluation field"",
}],
"additional_fields": [{ // fields that do not contribute to the impact evaluation
"name": "",
"type": "",
"value": "",
},{
"name": "",
"type": "",
"value": "",
}]
}Example Saturn record
{
"job_id": "abcdef",
"peer_id": "<Libp2p Peer ID>",
"started_at": "2023-05-01 00:52:57.62+00",
"ended_at": "2023-05-01 00:52:58.62+00",
"evaluation_fields": [{
"name": "num_bytes_sent",
"type": "int",
"value": 240,
},{
"name": "request_duration_sec",
"type": "in",
"value": 10,
},{
"name": "ttfb_ms",
"type": "integer",
"value": 35,
}],
"additional_fields": [{
"name": "status code",
"type": "integer",
"value": 200,
},{
"name": "cache_hit",
"type": "boolean",
"value": true,
},
...
]
}Example SPARK Record
{
"job_id": "abcdef",
"peer_id": "<Libp2p Peer ID>",
"started_at": "2023-05-01 00:52:57.62+00",
"ended_at": "2023-05-01 00:52:58.62+00",
"evaluation_fields": [{
"name": "status code",
"type": "integer",
"value": 200,
},{
"name": "signature_chain",
"type": "string",
"value": "<signature chain>",
}],
"additional_fields": [{
"name": "num_bytes",
"type": "integer",
"value": 200,
},{
"name": "ttfb_ms",
"type": "integer",
"value": 45,
},
...
]
}Evaluate
At this point we have a table of logs in the above data model. This table of logs is either on chain in the naive case, in an off-chain data store, or split between the local stores of each of the nodes in the network. The next step is to evaluate over the logs based on the evaluation function.
Evaluation Function
In general, for evaluation fields, for node where , and with logs and evaluations on those logs and evaluation function , we can calculate the evaluation output as
where and is the evaluation of node .
In the case of Saturn, the evaluation function is a function of number of bytes sent, TTFB and the request duration. This is calculated by the Saturn payouts system.
Spark
In the case of Spark, the evaluation function is simply a count of the number of successful requests with valid signature chains a Station has performed. Specifically, for node ,
where if the log with index of node is valid and otherwise.
Saturn
The Saturn evaluation function is more complicated . See https://hackmd.io/@cryptoecon/saturn-aliens/%2FMqxcRhVdSi2txAKW7pCh5Q for more details.
Two Step Evaluation
As we discussed in the measurement step, the evaluation can be conducted in two steps. One step locally by each node and then one step globally by the evaluation contract. In the Spark example, each node can calculate locally and submit on chain. Then the evaluation contract can calculate as a second step on chain.
Data Model
At the end of the evaluation step we should have an object that satisfies the following data model
{
"epoch": "3",
"measurement": "<cid-of-measurment>",
"trace_of_eval": {
...
},
"payees": [{
"node_id": "1",
"proportion": "0.4", // In above discussion, this is y_1
},{
"node_id": "2",
"proportion": "0.6", // In above discussion, this is y_2
}],
}I.e. for each epoch we know what proportion of the overall tokens will go to each node.
TODO could the above data model include structures to verify the evaluation step was perform correctly? Include hash of measurement commitment
Reward
The reward step is the most straightforward and we can lean heavily on the work that has already been completed by The Saturn Goes Web3 Working Group.
We invoke the rewards smart contract with the following information
{
"evaluation_contract": "f4..."
"fil_for_epoch": "2000"
}The reward contract then takes the amount of FIL from the reward contract account and splits the FIL between the nodes based on the results of the evaluation contract.
Smart Contracts
Membership Requirements
- Nodes must be able to register themselves to participate the IE
- Nodes may have to stake to register in an IE, depending on the fraud prevention system
- Nodes must be able to remove themselves from the IE
Measure Requirements
- In the naive model, nodes must be able to submit their logs into the measurement contract
- In the IPC model, nodes must be able to submit their logs into an IPC subnet
- In other models, the measurement step is non needed since we count the commitment and summary statistics submission as part of the evaluation step.
Evaluate Requirements
- Asynchrony: The evaluation process must not be blocked waiting for measurements to come in or for nodes to be available.
- The evaluation contract must be able to access the evaluation function
- In the Commitment & epoch summary on chain model, the evaluation contract must be able to challenge nodes to provide proofs of job inclusion.
- To reduce on chain costs, the evaluation must happen off-chain with proof of correct computation submitted on chain
Reward Requirements
- Asynchrony: Nodes should be able to claim all prior rewards at any point in the future
- The sponsor must be able to add funds for the payout in each epoch. They must be able to add payouts for multiple epochs in one transaction.
- The payout amount must be clear to the participants before they join and they should not need to trust the sponsor to pay up.
Smart Contract Functions
Evaluate
Reward
End of Original Document
Sync Notes
- For measurement step - first commit the logs all the way to on chain (ex through the centralized service) such that each L1 can see and validate that their jobs were accumulated into that commitment
- batch all the measurements of one epoch, form merkle proof, can check that all measurements accumulate into the file hash data structure
- need the measurement step committed on chain, not waiting for the evaluation
- process for gathering measurements and stamping into the chain is a first separate thing
- that stamping could happen across multiple different nodes
- if one party doing accumulation without any checks, gives them the opportunity to censor
- parties could also include their commitments on chain directly - they take on work of putting commitments on chain
- could be O(n) if they do this (each node aggregting their L jobs)
- nodes should be able to dispute that the aggregator green box didnt include their logs correctly
- want number of commitments to the chain to be as small as possible
- if dont trust aggregator green box doing job correctly, need another way to get data there
- either everyone needs to be able to run it, or needs a verifiable proof
- verification function needs to have access to data, be able to run verifiably off chain, and be verifiable on chain
- Changes vs design above
- make adding measurement it’s own step checkpointing on chain, as input to eval step (where need to verify computation done correctly)
- need some answer for “how do I flag if my data wasnt included in the aggregator measurement step”
- Saturn use case - have all commitments on chain, flag which one fraudulent, then put merkle tree accumulation of valid ones, and fraudulent ones, and then allow node to check which is there
- Dante wrote a fraud detection ZK thing that could lean on
- dont want fraud detection logic on chain
- lots of info - source and destination, timing, data, etc
- whether or not a request is abuse or not abuse - dont think need to separate that out and include two accumulations
- want the fact that the request thought to be abuse recorded and public
- but could be part of evaluation step (epoch, payees, but also trace of hash with relavent info)
- If you show them what is fraudulent, it helps attackers to figure out the strategy. Catching good players in the fraud camp who are honest will be awkward.
- FIL plus dispute logic. Open forum and have people deal with the complaints. Can we have different layers of triaging disputes?
- Could you do different layers of fraud detection if it is expensive to do the best fraud detection?
- Are there too many variables for everything to be decided “by the protocol”?
- Should we put the fraud cases on chain?
- could start with this in public, and then move to ZK (which defers some of the hard work, and allows iterating in public until get to scale)
- still make separate steps
- need to highlight some summary steps (bandwidth served, number of abuse requests, etc)
- want easy checking for bugs by legitimate nodes from what submitted
- Should the fraud algorithm be public?
- every time model changes, can change the commitment of the model on chain
- retriev protocol for disputes
- “you had this many success, this many failures in the epoch”
- the evaluation contract can contain a CID pointer to the evaluation function. Let’s say epoch 6 runs with new eval function to epoch 5.
- Time between evaluation results on chain and payouts unlocked to allow time for re-evaluation
- Separate the different models from the final model into different docs
- Figure out the upgrade framework for the code.
- Pipeline the different phase and get ahead on getting the dev shop.
- Design for privacy, and then we can loosen requirements if data can be public. Harder the other way around.
- Risk: getting signature chains into SPs in time
Next Steps
- Julian: Refactor the above design doc to separate the measurement and evaluation steps more clearly
- Julian: Focus on the Centralised Orchestrator & Fraud Detection model. Pull this out into a new design doc, leaving this one to act as motivation for why we chose this model. In this new design doc, we describe concretely what the commitment on chain is.
- Julian: Review above design doc and eradicate confusion in terminology about the off-chain storage.
- Julian: Sequence flows of particular events: registration, job submission, commitment submission.
- Julian: Review of fraud detection for Spark (and Saturn) in this model
- Julian: Review of how we publish fraud records on chain. Is this another commitment?
- Julian: Plan for minimal PoC within Station team and when we need to bring in the dev shop. Links to below milestones.
- Julian: Spend time with existing smart contracts and learn FVM
- Once new doc: Share with Amean and Miro
Work plan
- Ensure https://github.com/Zondax/filecoin-signing-tools/tree/master runs on Zinnia
- Figure out how to get initial gas fees
- Register membership using smart contract
- Stream logs into publicly available database (read public, write public, delete private)
- Commit logs on chain using smart contract
- Measure using smart contract
- Detect fraud based on measurements and centralized log storage
- Evaluate measurements using smart contract
- Reward based on evaluation results using smart contract